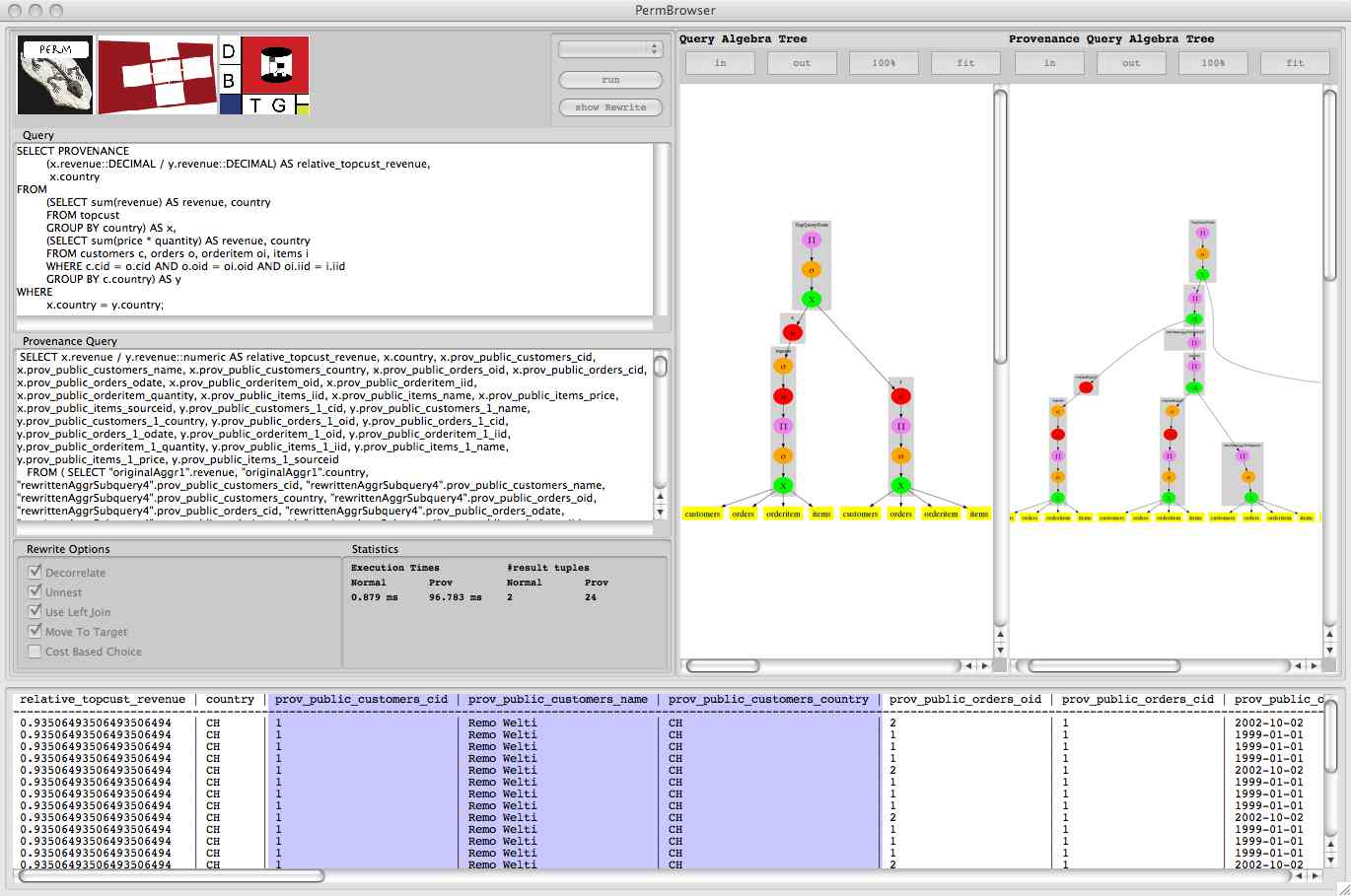



Data provenance is information that describes how a given data item was produced. The provenance of a data item includes source and intermediate data as well as the transformations involved in producing a concrete data item. In the context of a relational databases, the source and intermediate data items are relations, tuples and attribute values. The transformations are SQL queries and/or functions on the relational data items.
Existing approaches capture provenance information by extending the underlying data model. This has the intrinsic disadvantage that the provenance must be stored and accessed using a different model than the actual data. In the Perm project we try to overcome this disadvantages by developing a novel provenance management system called Perm (Provenance Extension of the Relational Model) that is capable of computing, storing and querying provenance for relational databases. Perm generates provenance by rewriting transformations (queries). For a given query, Perm generates a single query that produces the same result as q but extended with additional attributes used to store provenance data. An important advantage of the approach used in Perm is that the transformed query is also a regular relational algebra statement. Thus, we can use the full expressive power of SQL to, e.g, query the provenance of data items from the result of the original query, store the transformed query as a materialized view, and apply standard query optimization techniques to the execution of transformed query. Perm can be used both to compute provenance on the fly (i.e., at query time) and to store provenance persistently for future access. Perm also supports external provenance and incremental provenance computation reusing stored provenance information.
An important contribution of Perm is that it already covers a far wider range of relational algebra than existing systems. We demonstrated in extensive experiments that Perm can efficiently compute the provenance of complex queries (for example the queries from the TPC-H benchmark) while inducing only a minimal overhead on normal operations.
Unlike other approaches Perm has a 'pure' relational representation of provenance data and provenance queries. The provenance of query is represented as a single relation that contains the original query results augmented with provenance information. Provenance information is attached to a query result by extending the original result tuples with the contributing tuples from the base relations accessed by the original query. Thus, all attributes from the relevant base relations are appended to the result schema of the original query. To distinguish between original attributes and provenance attributes, provenance attributes are identified by a prefix and the name of the relation they are derived from.
For example, consider the following 'toy' query and its normal and provenance results:
SELECT * FROM r;
Original query result
|
Provenance query result
|
SELECT DISTINCT r.a FROM r LEFT JOIN s ON (r.a=s.b);
Relation r
|
Relation s
|
Original query result
|
Provenance query result
|
Perm computes the provenance of a query q by applying a set of algebraic rewrite rules that transform q into a provenance query q+. This query q+ generates the provenance representation introduced in the previous section. The rewrite rules are defined over an algebraic representation of a query and operate on a single algebraic operator. Each rule is defined over an input algebra expression and the list of provenance attributes of its input (P). The result of a rewrite rule is a transformed algebra expression and provenance attribute list. As an example consider the rewrite rule for the projection operator:
(ΠA (T))+ = ΠA, P (T+) (T+) with P ((ΠA (T))+) = P (T+)
In principle the rewrite rules are unaware of how the provenance attributes of their input were produced. This is a huge advantage, because it enables us to use the rewrite rules to propagate provenance information that was not produced by Perm. For example, Perm can compute the provenance of queries that include data that was annotated with provenance information manually or by another provenance management system.
For some operators there is more than one rewrite rule that produces the provenance of the operator. For this type of operator the choice of rewrite rule may influences the performance of the provenance computation. We provide a heuristic and a cost-based solution for choosing the best rewrite strategy.
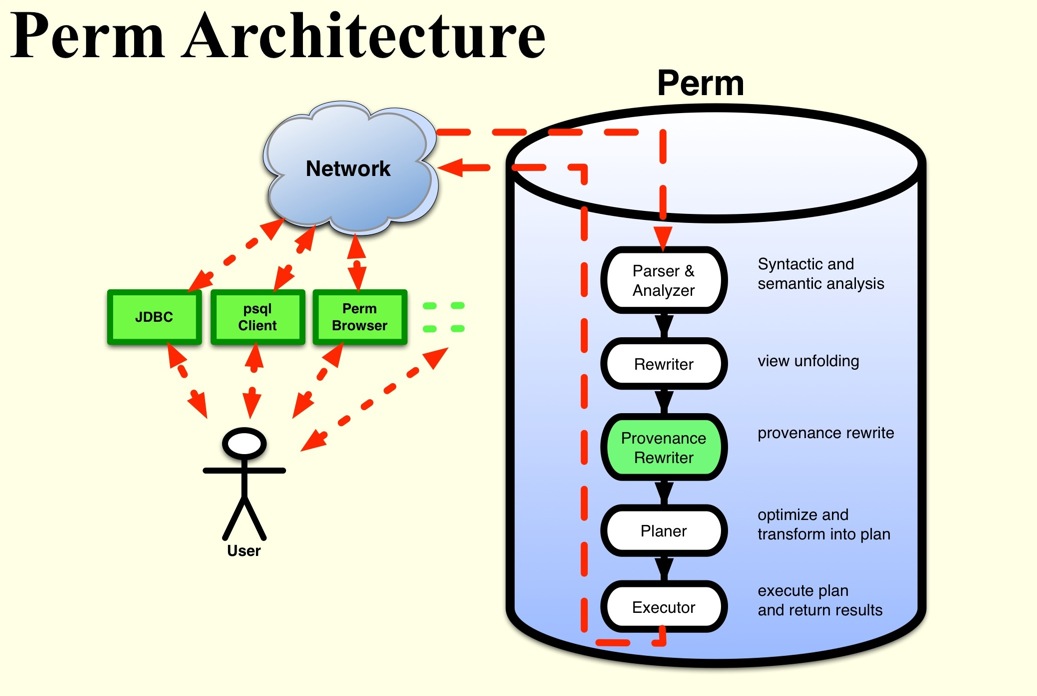
We have implemented Perm as an extension of the PostgreSQL DBMS (see Figure on the right). Perm operates on the internal query tree representation of a query. The output of the Postgres query analyzer is passed to the Perm rewrite module. The rewrite module traverses the query tree and applies the provenance query rewrite rules to transform the query (or part of the query) into a provenance query. The rewritten query tree produced by the Perm module is handed over to the Postgres query optimizer and, thus, Perm benefits from the query optimization techniques incorporated into PostgreSQL.
Provenance computation in Perm is triggered and controled by using the SQL-PLE (provenance-language-extension). The new keyword PROVENANCE marks a query for provenance computation:
SELECT PROVENANCE * FROM r;
The PROVENANCE keyword has an optional modifier ON CONTRIBUTION which is used to select the desired contribution semantics. Currently Perm supports two types of contribution semantics: influence contribution semantics (I-CS) aka Why-provenance and a form of copy contribution semantics (C-CS) which is a form of Where-provenance. For instance:
SELECT PROVENANCE ON CONTRIBUTION (influence) * FROM r;
Note that all original SQL features provided by PostgreSQL are not affected by the language extension, and even more important, they can be used in combination with provenance computation. Therefore a user cannot just receive provenance information, but also query provenance information, store it as a view, etc.
Perm supports incremental provenance computation by allowing the manual specification of provenance attributes of a relation or subquery, and providing language constructs to stop the rewrite process at a certain point. E.g., consider a query over a view where the user is interested in the tuples from the view that contributed to the query result (in contrast to the base relation tuples that contributed to the query result). The keyword BASERELATION is appended to a subquery or view to instructed Perm to handle it like a base relation. To manually specify the provenance attributes of a view, base relation or subquery, the keyword PROVENANCE followed by a list of attribute names has to be appended to a FROM-clause item. For inistance, consider the following queries defined over view v1:
SELECT PROVENANCE * FROM v1 BASERELATION;
In this example view v1 will be handled like a base relation. Therefore, the rewrite rules are not applied to the view definition of v1, but the attributes of the view query result are renamed and attached to the query result. For the second example assume that v1 has an attribute provAttr that stores manually created provenance information:
SELECT PROVENANCE * FROM v1 PROVENANCE (provAttr);
In this query PROVENANCE (provAttr) instructs Perm to not generate provenance information for v1, but instead use attribute provAttr as the provenance for v1.